

Why panel data, and why it’s hard

A new version of panelView has just shipped. Before getting into the importance of visualization, I want to step back and explain the bigger picture: why the use of panel data has become so popular for causal inference, and why doing it well with observational data is genuinely hard.
Causal inference with panel data?
When I say this Substack is mostly about causal inference and panel data, I have a particular framing in mind. Modern causal inference, at least as I understand it, has a few defining features.
First, it separates identification from estimation. That means being explicit about the assumptions that connect observed data to unobserved quantities such as counterfactual outcomes. These differ from modeling restrictions that constrain the potential outcome process, such as assumptions about functional form, restrictions on interference, or treatment effect homogeneity.
The boundary is sometimes blurry, though. The parallel trends assumption, for example, is in my view primarily an identification assumption, but it is also a structural restriction on untreated potential outcomes. SUTVA / non-interference is also seen by many as an identification assumption.
Second, be less dependent on functional form. Modern causal inference tries to be as agnostic as possible about functional form. Instead of relying on parametric assumptions for identification, it often looks for designs in which causal comparisons are justified by the assignment mechanism or by transparent restrictions on potential outcomes.
RCTs are the cleanest example. When modeling is unavoidable, the goal is often to use flexible methods, as in the double machine learning literature, while keeping the identifying variation conceptually separate from the prediction model.
Third, clear estimands. Modern causal inference is explicit about the inferential target: the estimand, or the quantity of interest. In the Neyman-Rubin tradition, a causal estimand compares actuals and counterfactuals of the same group of units, whereas a purely statistical estimand does not necessarily do so. Moreover, is the estimand population-based or sample-based? What is random, and what is fixed? These distinctions matter, because they shape how we think about uncertainty.
Given the estimands and assumptions, especially the identification assumptions, the choice of estimation strategies becomes, in my view, less crucial.
Why panel data are so popular
In economics, Paul Goldsmith-Pinkham finds that over one-fifth of NBER working papers, and of articles newly published in top journals, use difference-in-differences (DID) in the Card-Krueger tradition, broadly defined, as shown by the figure below.
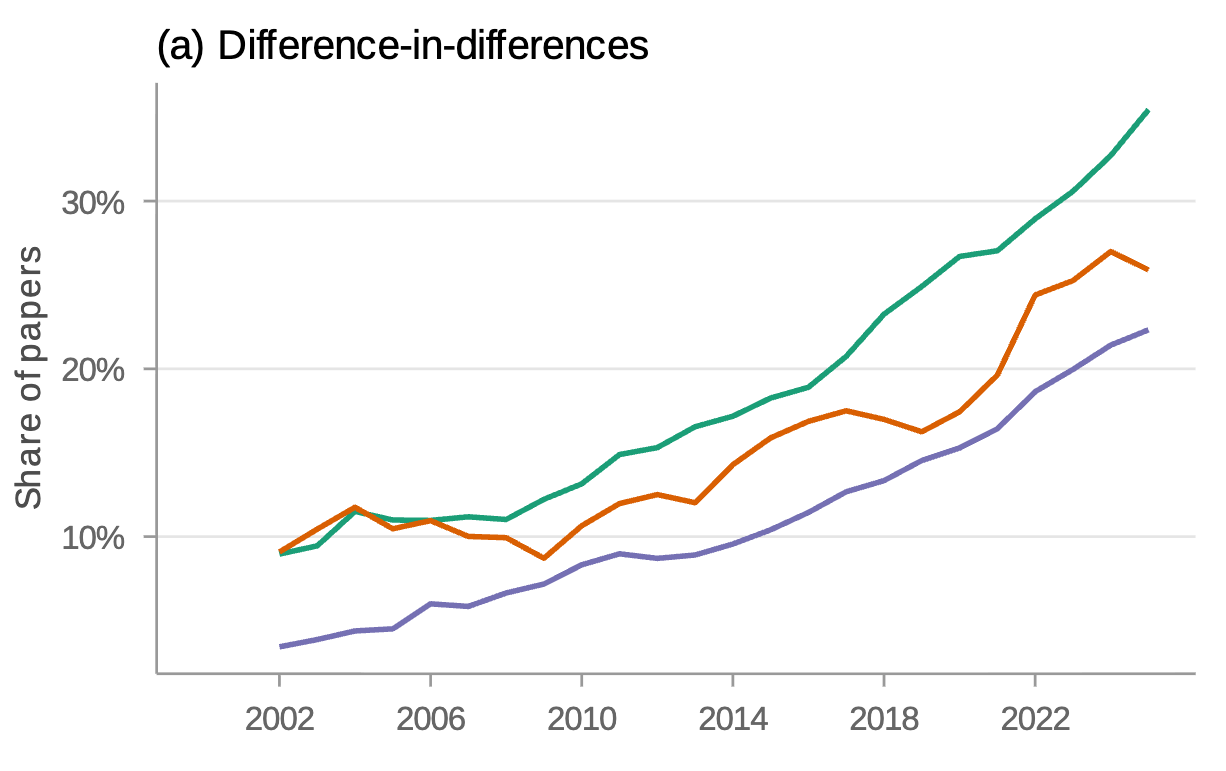
In political science, I find a similar pattern in APSR, AJPS, and JOP. More recently, my coauthors and I show, based on our recent study of more than 90,000 published articles, that the share of DID papers in political science is also rising sharply beyond top journal publications.
It is no exaggeration to say that, at least in economics and political science, panel methods have contributed significantly to the credibility revolution, especially in recent years.
Why is this? I think there are three reasons. The first two are mostly practical.
Data availability. Country-year, state-year, and individual-level longitudinal data are far more available today than they were twenty years ago.
The difficulty of alternatives. Other non-panel approaches to causal inference have become harder. Field experiments are expensive to run, good instrumental variables are hard to find, and regression discontinuities are relatively rare and often underpowered. Some also question whether survey experiments can mimic real interventions. The credibility bar has risen across the board, and many researchers end up turning to panel data partly by default.
Dealing with unobserved confounding. Many researchers believe fixed effects are a general solution to unobserved confounding, and for that reason, the more fixed effects the better. This appears to be a strong belief, and only recently has the econometrics literature begun to challenge it more directly. My friend Anton has a very interesting analysis of three-way fixed effects.
The promise
I do believe that panel data, done right, offers a path toward credible causal identification. At a high level, this is not surprising, because panel data gives us two dimensions to work with.
The first is the unit-time structure. A unit’s past is often highly predictive of its future.
The second is the presence of a comparison group. In many settings, predicting the average counterfactual in the same period is easier than forecasting the future based on past information only.
Together, these two features strengthen identification in a way that is conceptually simple and intuitively appealing. The key question is whether the potential outcome processes are stable or comparable enough that past outcomes and comparison units provide valid information about missing counterfactuals.

This promise is part of why panel methods became so popular. Among them, DID, probably due to its simplicity, is the most widely used. We will return to their fragility and complications in later posts.
Strange things
What strikes me as somewhat strange about causal inference with panel data is how long two-way fixed effects (TWFE) remained dominant. Because of that, the way panel data has commonly been used for causal inference remained heavily parametric, which sits somewhat awkwardly with the principles I just described.
Only relatively recently did the literature fully recognize that TWFE can implicitly compare units under very different treatment histories, producing weighting and extrapolation problems when effects vary across cohorts or over time. I think this is only the tip of the iceberg.
The persistence of conventional practice says something important about how difficult it is to apply these principles within the panel framework. It is simply hard.
Why difficult?
Here I mention four reasons.
1. The hypothetical experiment is complex. In cross-sectional settings, observational causal inference often uses experiments as a benchmark. In panel settings, however, the design of experiments is less developed and less well understood, partly because the problem itself is genuinely more complicated.
Panel experiments are inherently high-dimensional: the space of possible treatment paths or policy sequences can become very large, and interference is pervasive. We will come back to this in later posts.
As Guido and others remind us, the idea that experiments are easy to analyze deserves a serious second look. Over time, the field has recognized many subtle complications even in randomized settings, and especially in panel ones.
2. The basic constraint of observational data. With observational data, nature or other forces dictate how the treatment is assigned, about which we often have little knowledge. The best we can often do is to argue that, after conditioning on some fixed effects, assignment is “as good as random.” In many applications, I find that defense thin.
3. Strong dependence in a sample, and the absence of repeated i.i.d. samples. This third challenge is especially acute in the kinds of data political scientists often study. Within a single panel, the amount of genuinely idiosyncratic information that allows for identification is often much smaller than the apparent sample size suggests. Power is a major concern.
Moreover, we cannot replay a country-year panel, and there is only one U.S. state-year panel. This differs sharply from many machine learning settings, where one might observe thousands of independent panels, such as videos or user trajectories that are sufficiently independent of one another.
4. Interference. Interference is distinct from serial correlation in potential outcomes. It is about spillovers of treatment effects across time or across units. My friend and collaborator Ye wrote his dissertation on it.
To give a simple example, anticipation effects and carryover effects can be seen as spillovers over time. Even if we are willing to assume that treatments do not spill across country or state borders, which is already a strong assumption, the temporal dimension remains.
Once interference is present, the usual move is to expand the indexing of potential outcomes. For a binary treatment over 20 periods, if we allow arbitrary anticipation and carryover effects, we no longer just have Y(0) and Y(1). At each time t, the potential outcome depends on the full treatment history:
That already implies 2^20=1,048,576 possible potential outcomes, with only one observed outcome! Setting overlap aside, this is a very low observable-to-unobservable ratio. In other words, causal inference with panel data is fundamentally a problem of missing high-dimensional potential outcomes. And this is before introducing treatment intensity or spatial spillovers.
So what does credible causal inference with panel data look like, given all this? My reading is that, in practice, researchers simplify the problem in two main ways.
First, they simplify the treatment histories by focusing on settings such as block assignment, staggered adoption, and the loosely defined “event studies.” Much of the DID literature has converged precisely on these cases. I am sympathetic to this effort—“better LATE than nothing,” in spirit.
Second, they put restrictions on the functional form. Researchers often take the TWFE specification (or specifications with more fixed effects) very seriously. The messy world is tractable again, but with unbelievably strong assumptions.
Once these challenges are taken seriously, it becomes difficult to feel fully comfortable with many conventional panel analyses interpreted causally.
In some sense, modern DID succeeded not because the panel problem became easy, but because the field converged on the narrow class of settings where the assumptions are easiest to state and defend.
We will return to many of these issues in later posts.
P.S.
I have been thinking about how formal these posts should be. Should I include reference lists? Should I thoroughly survey the literature so that all important work is covered? I think that may be too constraining. Recency and accessibility biases will inevitably shape what I cite or mention. I trust that readers will correct me when I make a serious mistake.
> "What strikes me as somewhat strange about causal inference with panel data is how long two-way fixed effects (TWFE) remained dominant"
I'm a student at UC Berkeley who's working for a grad student on a project that has required to me learn more about the modern DiD schemes when treatment is assigned at different time periods e.g. Stacked DiD, and I thought I was going insane when I thought this too!
To respond to your last question, I think reference lists (at the end) would be useful (as a student), but I think you ought to minimize formality (subject to some information threshold/thoughtfulness). You should also probably just write about what interests you, and that it's fine to have posts of varying levels of complexity.
I've been a fan of your work; looking forward to read more of this blog
Re: reference question. not a thorough lit review but a citation or two to give interested readers a head start could be useful